|
Listen to this story
|
An ML model is a collection of rules and preferences applied to a dataset, which enables computers to make predictions. Learning includes collecting data, cleaning it, and training the model using more powerful algorithms and/or new datasets. Once trained, your computer can make predictions with high accuracy over many cases.
While there are techniques like gradient descent, transfer learning, batch normalisation, etc, for enhancing models, there are various algorithms that are useful for solving different types of problems and training a model.
This article covers algorithms for training machine learning models, including neural networks, bayesian inference, and probabilistic inference.
Neural Networks
Forward Forward Propagation
A recent research discussed by Hinton at NeurIPS, titled ‘The Forward-Forward Algorithm: Some Preliminary Investigations’, was built around the idea of what machine learning may look like in the future if backpropagation were to be replaced. The research, which calls it the Forward-Forward algorithm, may mark the start of yet another deep learning revolution.
The Forward-Forward algorithm more accurately mimics the workings of the human brain. The FF algorithm aims to replace the forward and backward passes of backpropagation with two forward passes that move in the same direction but use different data and have opposing goals. One forward pass modifies weights to increase goodness in every hidden layer, and the other forward pass modifies weights to decrease goodness.
Backpropagation
The backpropagation algorithm works by iteratively adjusting the weights and biases of the neural network to minimise the error between the predicted output and the true output. It does this by using the gradient of the error function with respect to the network weights and biases, which tells us how much the error will change if we change the weights and biases.

To do this, the algorithm starts by making a prediction using the current weights and biases of the network. It then calculates the error between the predicted output and the true output. The error is then back propagated through the network, starting at the output layer and working backwards through the hidden layers, to calculate the error in the gradient with respect to weights and biases at each layer. The weights and biases are then updated based on this gradient, and the process is repeated until the error is minimised or some other stopping criteria is met.
Contrastive Method
Contrastive methods in neural networks involve learning a representation of a data point by comparing it to other data points in the dataset. The goal is to encode the data in such a way that similar data points are encoded similarly and dissimilar data points are encoded differently. This is achieved through the use of contrastive loss, which is a loss function designed to push similar data points close together in the representation space and push dissimilar data points farther apart.

For example, a common application of contrastive methods is in the context of self-supervised learning, where a neural network is trained to predict whether two input data points are similar or dissimilar. The network is then trained to minimise the contrastive loss by correctly predicting the similarity of the input data points.
Also read: The history of machine learning algorithms
Probabilistic Inference
Viterbi Algorithm
A dynamic programming algorithm for finding the most likely sequence of hidden states – called the Viterbi path – results in a sequence of observed events, especially in the context of Markov models. It is commonly used in natural language processing and speech recognition to find the most likely sequence of words in a sentence, given the sequence of sounds that make up the sentence.

Belief Propagation
Belief propagation, also known as the sum-product algorithm, is a method for efficiently computing marginal probabilities in graphical models. Graphical models are used to represent relationships between different variables in a system, and belief propagation is a way to efficiently compute the probability within any subset of the variables provided the values of the other variables are given.
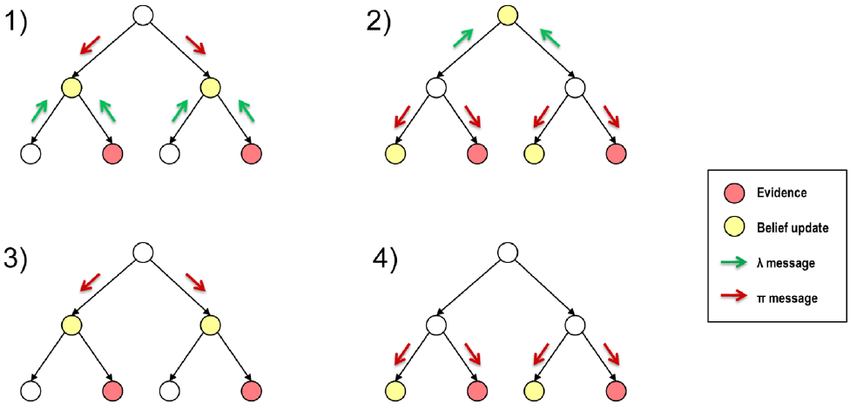
Bayesian Inference
Variational Inference
Variational inference is a method for approximating complex probability distributions using a simpler distribution. It is often used in Bayesian statistics, where the goal is to infer the posterior distribution of a set of latent variables given some observed data.
The basic idea behind variational inference is to introduce a set of variational parameters that control the shape of the approximating distribution. The goal is to find the values of these parameters that minimise the difference between the approximating distribution and the true posterior distribution.

To do this, we define a measure of the difference between the two distributions, known as the KL divergence. The KL divergence measures the amount of information lost when approximating the true posterior distribution with the approximating distribution. The goal is to find the values of the variational parameters that minimise this KL divergence.
Expectation-maximisation
Expectation-maximisation (EM) is an iterative method for finding maximum likelihood estimates in statistical models, especially those involving latent variables. It is an important algorithm in machine learning and has numerous applications, including in clustering, density estimation, and missing data imputation.

The EM algorithm consists of two steps – the expectation step (E-step) and the maximisation step (M-step). In the E-step, the algorithm estimates the expected value of the latent variables given the current estimate of the model parameters. In the M-step, the algorithm estimates the model parameters that maximise the likelihood of the data given the expected values of the latent variables from the E-step.