


|
Listen to this story
|
Researchers from EleutherAI have introduced Llemma, an open language model designed for mathematics, along with a Proof-Pile-2 dataset. This project, which is built with continuous pretraining of CodeLlama, has garnered significant attention in the academic and research community.
Check out the GitHub repository here.
Llemma stands out by offering both 7 billion and 34 billion parameter models, surpassing the capabilities of all other open base models, including Google’s Minerva, even at similar model scales. The achievement is particularly noteworthy as the 34-billion parameter Llemma model approaches the performance of Google’s Minerva, which boasts 62 billion parameters, despite having just half the parameters.
This new development from EleutherAI not only parallels Minerva, a closed model specially designed for mathematics by Google Research but also manages to exceed Minerva’s problem-solving capabilities on an equi-parameter basis. Notably, Llemma’s capabilities extend to a broader spectrum of tasks, including tool use and formal mathematics, which further distinguishes it in the realm of mathematical language modeling.
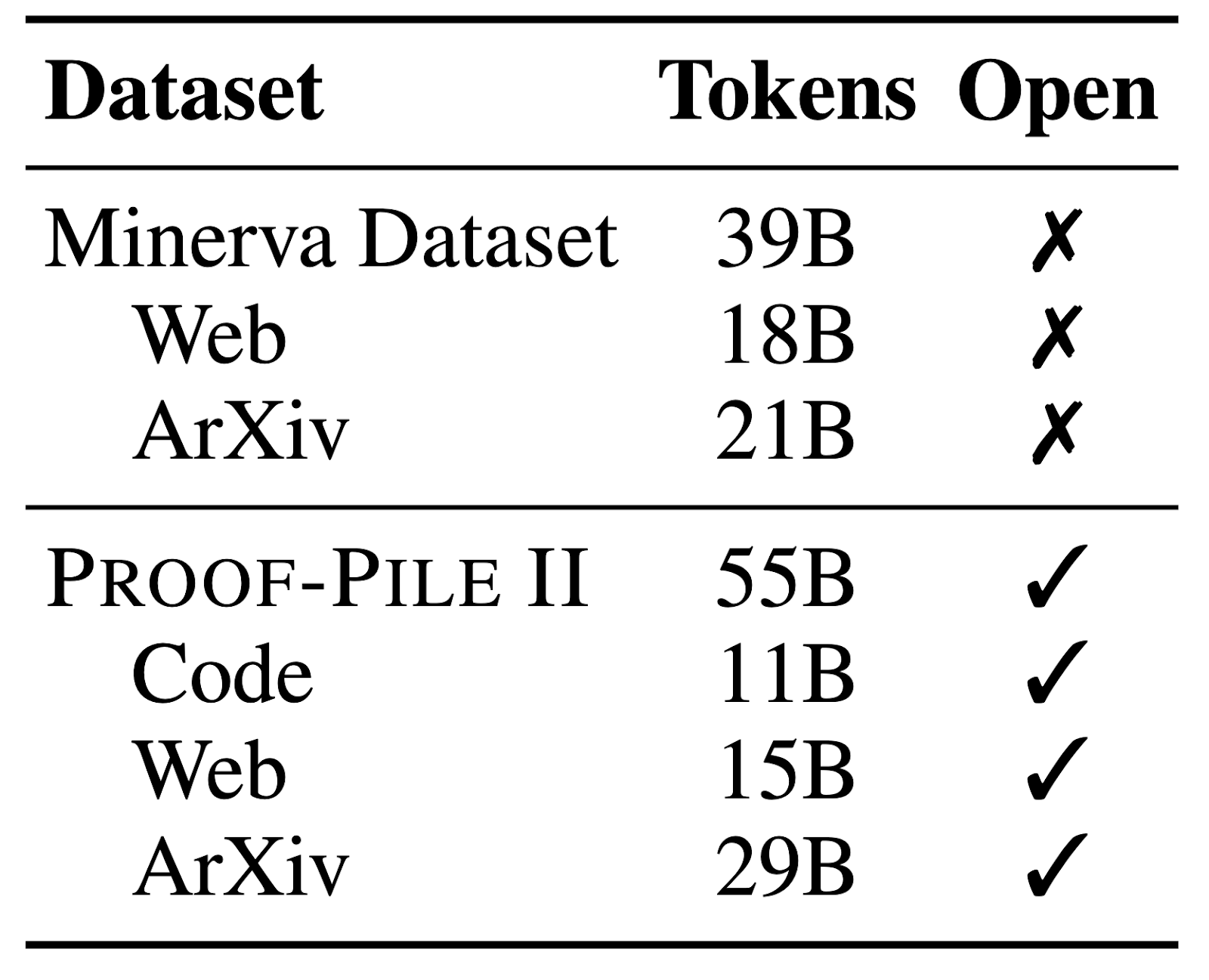
Zhangir Azerbayev, the lead author of the paper, describes that the journey toward creating Llemma began with the assembly of a vast dataset of mathematical tokens, encompassing the ArXiv subset of RedPajama, the recent OpenWebMath dataset, and the introduction of the AlgebraicStack, a code dataset tailored specifically for mathematics. This comprehensive approach resulted in training on an astounding 55 billion unique tokens.
Llemma’s models were initialized with Code Llama weights and subsequently trained across a network of 256 A100 GPUs on StabilityAI‘s Ezra cluster. The 7-billion model underwent extensive training, spanning 200 billion tokens and 23,000 A100 hours, while the 34-billion model received 50 billion tokens of training over 47,000 A100 hours.
In addition to its exceptional performance on chain-of-thought tasks when compared on an equal-parameter basis with Minerva, Llemma benefits from majority voting, providing an extra boost to its performance.
The collaborative effort of institutions such as Princeton University, EleutherAI, University of Toronto, Vector Institute, University of Cambridge, Carnegie Mellon University, and University of Washington has culminated in the creation of Llemma.











































































