



|
Listen to this story
|
If you are a beginner in the machine learning field, you might get bombarded with a deluge of information and tech jargon that are not always easily understandable. Comprehending common AI terms—a lot of which comes from maths (unfortunately)—is a difficult task if one is starting from scratch and has no technical background.
We compiled a list of some of these common machine learning terms that are used in every project and explained them in as simply—and with as little maths—as possible.
Classification
The basic step of machine learning is prediction of values based on the input values and Classification deals with identifying and separating data points into different groups based on the training data.
For example, identifying ‘spam’ and ‘not spam’ based on the input data or differentiating handwritten characters based on the set of known characters.

Regression
Another method for predictive modelling based on supervised learning, Regression involves predicting a numerical result based on the input data point. In other words, it involves determining a causal relationship between the input (independent variable) and the output (dependent variable).
For example, predicting the price of a house based on features and location of the house.

Read: 10 Evaluation Metrics for Machine Learning Models
Underfitting
When the training data is insufficient for the model to learn, it may fail to identify the best fit for the dominant trend. This is called underfitting. This often happens when the training of a neural network is stopped and is not training long enough on sufficient data, thus reducing the accuracy and reliability of the model.
For example, underfitting happens when it is assumed that the data is linear while it mostly is not.
Overfitting
Contrary to underfitting, overfitting occurs when the model is trained on too much data and gets moulded to learn from noise and inaccurate data. This results in the model trying to cover all data points present in the given dataset reducing the accuracy of the model.
Overfitting also occurs when the model is trained on the training data for too long resulting in high performance on the training data but not on real values.

Loss function and Cost function
To test the accuracy and calculate the error between the actual and predicted value of a single data point, loss function is calculated. This helps in evaluating the accuracy of the model.
Cost function is the aggregate difference of the entire training dataset. This is to calculate the sum of error for multiple data. Both terms are often used interchangeably.

Check out the series Techie-la Shots by AIM Media Studios to learn about Artificial Intelligence and Machine Learning from a beginner’s perspective.
Neural Network
As we can guess from the name, Neural Networks refer to those types of ML models that try to mimic the working of a human brain. These are usually represented graphically and consist of simple mathematical operations combined to perform complicated tasks using different layers connected together.
Simply explained, Artificial Neural Networks have different layers for input, processing, and output much similar to how vision works in humans.

Parameters and Hyperparameters
Known as ‘weights’, Parameters are the values that the ML model learns directly from the training data. These values define the skill of the model and are inserted by the practitioners. The parameters are continuously updated using optimisation algorithms. These are estimated during the training process.
Hyperparameters are also parameters but these values control the learning process and tuning of the model. They are specified parameters that are essential for optimising the model and are always external and independent of the dataset like the activation function.

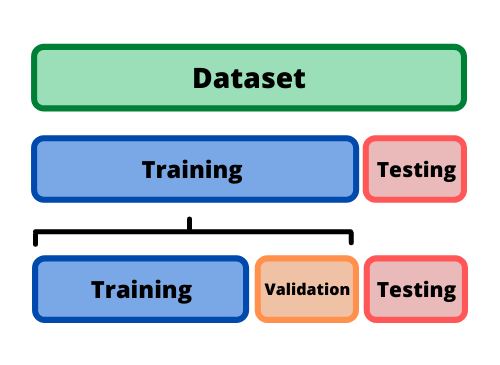
Validation and Test Data
Some of the training data is held back while training the model that is later used to estimate its skill and efficiency, called the validation data. This is used for fine-tuning the hyperparameters of the model.
On the other hand, test data is the dataset on which the final built model is evaluated. The testing data is unlabelled—as opposed to the training and validation data—and thus proves the real world application of the ML model.
Read: Top 10 Machine Learning Algorithms for Beginners to Dive Into














































































