


In recent news, a new study from the researchers of Nvidia introduces an AI-based technique to generate talking heads for video conferences by combining a single 2D image and unsupervised-learning 3D keypoints. This technique allows for several manipulations such as rotation of a person’s head, motion transfer, as well as video reconstruction.
Producing Talking Heads
This model learns to use a source image that contains the target person’s appearance along with a driving video (many times obtained from another person) that dictates the motion in the output video. These two inputs are then used to synthesise a talking-head video of the person. This model uses canonical keypoint representation where the identity-specific and motion-related information is decomposed unsupervised.

Since only the keypoint representations are sent to reconstruct the source video at the receiving end, in addition to outperforming previous similar experimentations in tests using benchmark datasets, this AI also achieves H.264 quality video but by using just one-tenth of the bandwidth. This model further reduces the bandwidth requirement by using an entropy coding scheme.
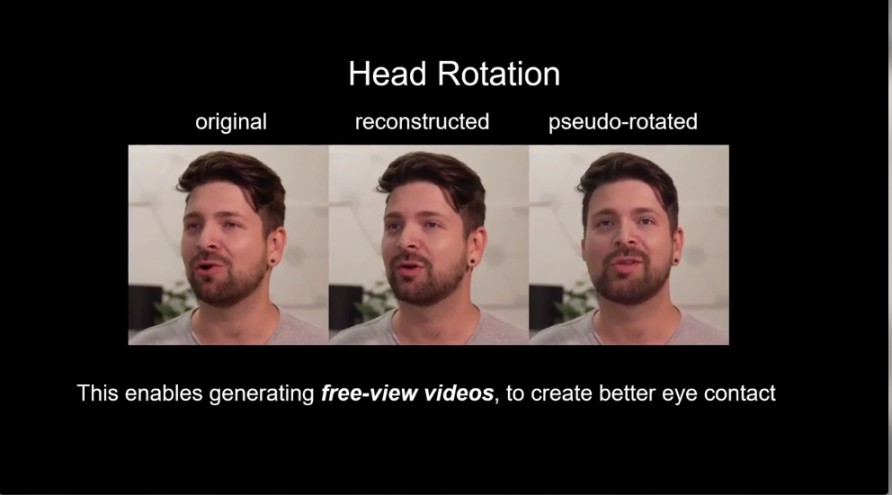
Considering the limitations of previous models, the authors write that the existing 2D-based one-shot talking-head methods also come with their own set of limitations. One of the key limitations is the absence of 3D graphics models, which, in turn, can only synthesise the talking-head from the original viewpoint, and cannot render it from a novel view.
The model addresses this limitation of a fixed viewpoint by achieving local free-view synthesis, which is a method of synthesising full view using images freely distributed in the scene.
Using 2D-based methods instead of 3D graphics-based model offers several advantages such as:
- Compared to the 3D graphics-based method, the acquisition of which is difficult and expensive, 2D methods are much cheaper.
- 2D models are better equipped at handling the synthesis of subtleties such as hair and beard, whereas acquiring detailed 3D geometries of these regions is a challenging task.
- 2D-based methods can directly synthesise accessories such as eyeglasses, hats, and scarves, that may be present without their 3D models.
In addition to synthesising more realistic results, this research outlines several other benefits:
- By modifying the keypoint transformation, the model generates free-view videos
- The keypoint transformations achieve better compression ratio as compared to the existing methods
- It dramatically reduces the bandwidth requirement, which could change the future of video conferencing for good.
The full paper can be found here.
Similar Techniques From Nvidia
There have been a few attempts earlier from Nvidia to use AI for video generation and manipulation. Two of them, in particular, are:
vid2vid: In vid2vid video synthesis, videos of human poses or segmentation masks are used to output photorealistic videos. This approach uses a GAN framework applied through generator and discriminator architecture. The output so received is high-resolution, photorealistic, and coherent video results. But as discussed in previous sections, this is a high-cost and laborious task as we are inputting video segments as opposed to 2D images as in the case of the Nvidia study.
Maxine: In October, Nvidia had introduced Maxine, a video conferencing service, that uses Nvidia’s GPUs to process and boost call quality with the help of artificial intelligence. This platform uses AI to realign faces and gazes to make appear that the user is always looking at the camera. Further, like the latest model, Maxine also uses key facial points to reduce the bandwidth requirement to one-tenth of the H.264 streaming video compression standard.
Wrapping Up
With the given scenario where businesses are working from home, video conferencing has seen an upward trend to stay connected and coordinate on daily tasks. This has also prompted rapid innovation in this department.
With techniques like these, Nvidia is competing with video conferencing platforms such as Microsoft Teams and Zoom, which are also using AI techniques to improve video call experience by introducing features like blur backgrounds and power augmented reality animation and effects.

















































































